ChatGPT本周如此大热,我都被朋友们催稿了,不过作为AI领域的前沿参与者,我也认为有必要聊聊这个话题。前几天体验了ChatGPT的效果,不仅感慨它专业的回答与人类如此接近,而且与之前AI作画、AI写诗对比,ChatGPT还会写程序,让我这个写了二十年程序的码农感受到了面临失业的威胁。今天主要聊聊ChatGPT的原理,让我们从创造者的视角去俯视它,找回我们人类在AI面前的尊严和优越感。
原理推测
由于OpenAI没有直接公布ChatGPT的论文和原理,我从官网上看到两个核心信息:一是提到“ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.”,因此研究InstructGPT是一个线索。二是ChatGPT的原理图和InstructGPT论文中的原理图几乎是一致的。由此推测,从理解原理的角度,直接用InstructGPT的论文可以八九不离十了。
GPT的基本工作模式
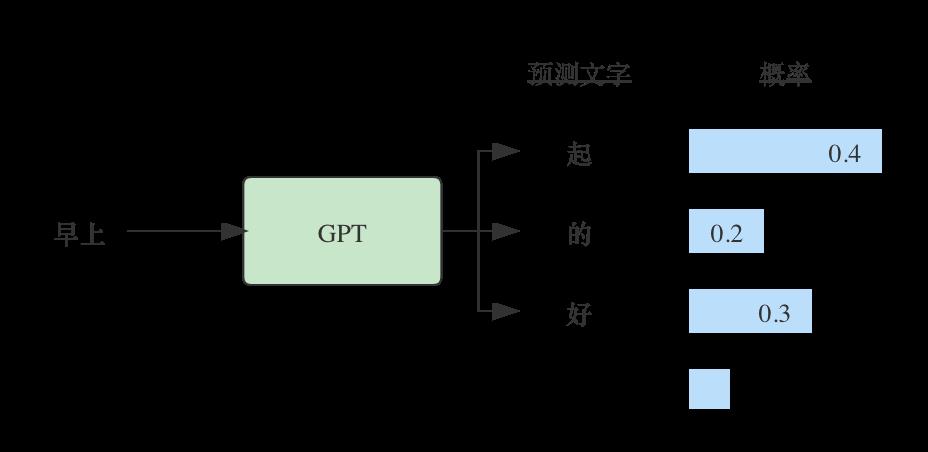
GPT模型的工作方式是按一个一个文字来生成的,比如输入“早上”,它会输出所有可能跟随的字,以及它们的概率。比如“早上起”,“早上好”,“早上的”,等等。在选择了其中一个输出之后,再把这个输出作为输入,让模型预测下一个字的输出,比如选择了“早上起”。
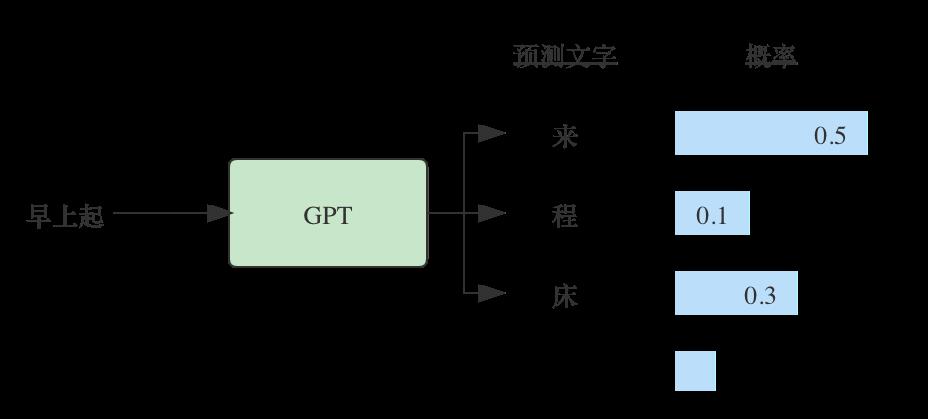
GPT接收到“早上起”之后,给出了后面接哪个字的概率。看到这里有人可能会担心是否每次都输出相同的结果,其实不会的,模型有随机的因素,多数情况下会输出不一样的结果。
大模型与Fine tune
监督学习的弊端是需要有标注数据,但这从数据规模上限制了模型和效果。Bert模型巧妙地利用了“完型填空”的方式,实现了自然语言处理模型的自监督学习。形式如下:
给出一个句子:手机听歌APP可以使用QQ音乐、 网易云音乐 、酷狗音乐、酷我音乐等。输入给模型时,可以先盖住一个词,让模型去预测,然后告诉模型正确答案以修正模型参数。
由于这种方式不需要人工标注,所以可以大量地使用,也由此进入了大模型时代。GPT-3模型具有训练参数1750亿个,数据量45TB,训练费用超过1200万美元。
大模型毕竟是一个基础模型,在具体应用场景时需要场景数据对模型做一些微调,也就常说的Fine tune。
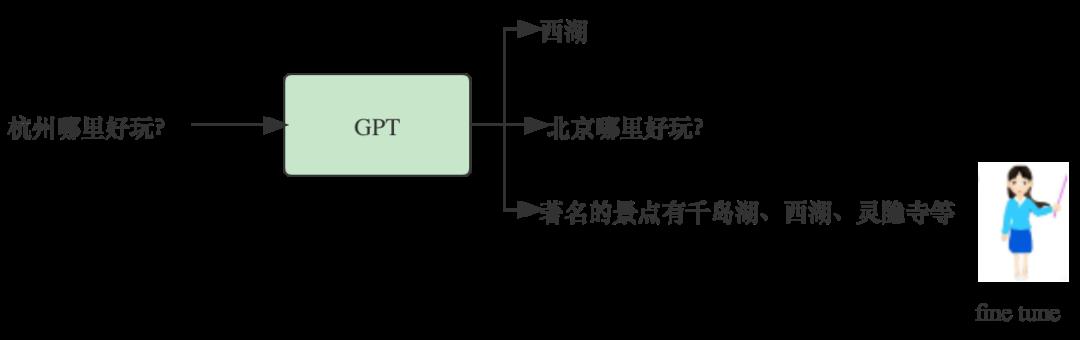
由于GPT使用的训练数据来自于网上材料和公开资料,不一定符合人类问答场景的需要。如果有一个资料是一个目录,里面索引了各地旅游的标题:杭州哪里好玩?北京哪里好玩?西安哪里好玩?等。很显然我们问GPT一个问题,不希望它反过来问我们一个问题,我们要的是答案。另外西湖和杭州同时出现的次数肯定很多,如果按统计概率,它可能会只回答西湖,但作为一个要来杭州旅游的人来说,回答应该尽量包含更多的景点介绍,这样更完整一些。这种情况下,我们用人类写一个回答,让模型去学习。由于只是Fine tune,人类提供的数据量不会太多,只是让模型学习一下人类的偏好。
打分模型

GPT模型经过fine tune之后,虽然学到了人类的偏好,会输出一些让人类更满意的回答,但哪些回答是最优的呢?它还需要人类的指导。
“打分模型”用于训练人类对不同回答的评分,模型的数据,需要人类的参与。据说这次ChatGPT公开测试就是为了收集人类的数据反馈。开放不到一周,注册用户就超过100万了,人类参与很积极。
通过强化学习选择最优结果
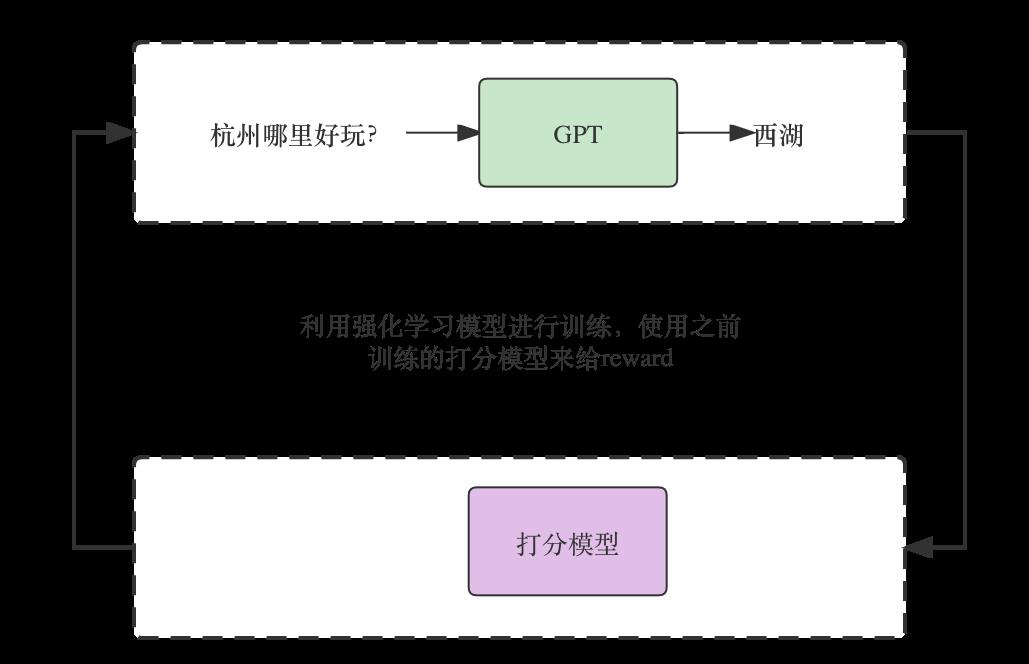
打分模型为强化学习模型提供Reward,对符合人类偏好的输出给予高分奖励,对于人类不喜欢的输出给予低分进行惩罚。
至此,ChatGPT的基本原理就介绍完了。概括一下:
-
利用自监督学习来训练一个大语言模型
-
利用少量人类答案进行finetune
-
利用人类选择信息有监督训练一个打分模型
-
利用强化学习根据打分模型的评分优化选择
感觉这个模型把最近十年AI领域的高端利器都用上了:自监督深度学习、有监督学习、强化学习、大模型,大规模GPU、大规模CPU,人类参与共创等。所以发展潜力还是很大的,对效果可以进一步期待,但同时也能看到了,由于原理上没有跳出当前的框架,也会有着相当的局限性。