前言
ChatGPT的大火也引起对其原理的思考,本篇文章主要探索ChatGPT背后的技术原理,并结合自己及周边同学使用后反馈带来的一些思考。
ChatGPT注册使用方式见另一篇文章:ChatGPT以鸡你太美主题写小说
InstructGPT
ChatGPT其原理与InstructGPT类似,因此我们主要看一下InstructGPT是如何实现的。
参考链接:Training language models to follow instructions with human feedback
工作原理
InstructGPT工作原理如下:
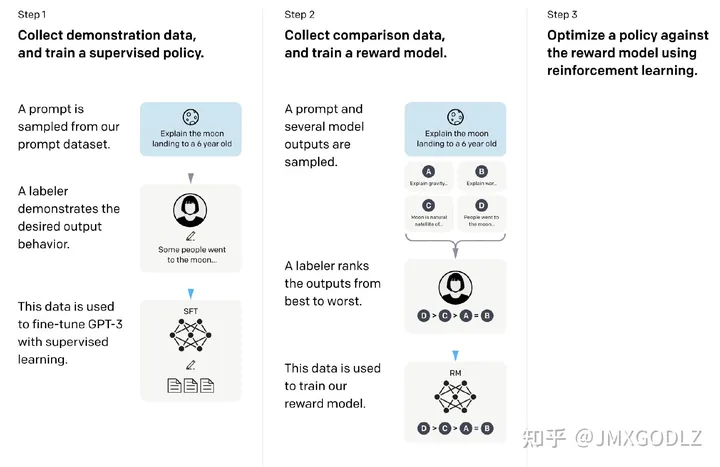
InstructGPT训练分为三步:
SFT:收集Prompt数据集,根据GPT3进行有监督微调训练。
RLHF:收集人群反馈的数据集,进行强化学习训练。
FT:根据第二部的模型预测reward,并根据PPO算法进行有监督微调训练。
主要贡献
- 相较于GPT3输出的结果,标注者偏好于InstructGPT输出的结果
- 相较于GPT3输出的结果,InstructGPT输出结果在真实性上取得提升
- 相较于GPT3输出的结果,InstructGPT输出结果在“毒性”上取得小幅度提升
- InstructGPT 模型对 RLHF 微调分布之外的Prompt有更好的泛化性。
- 公开的NLP数据集不能反映语言模型的使用方式
- InstructGPT仍然会犯简单的错误
总结
- InstructGPT生成的结果更符合标注者预期,真实性也更好
- InstructGPT对输入的Prompt泛化性更好
- 公开NLP数据集的评估方式不能反映InstructGPT模型效果
- InstructGPT仍然会犯简单的错误
思考
在使用ChatGPT的过程中,根据身边同学反馈及自身的体验,我整理了以下的问题,里面的回答也只是个人思考,欢迎讨论指正:
Q1: ChatGPT生成过程是否根据搜索结果来进行生成?
身边有同学反馈,ChatGPT输出的结果和xx产品文档一模一样,那么是否ChatGPT是根据搜索结果来进一步生成呢?


我觉得并不是,我拿了一些官网介绍的说明文档进行提问,但是ChatGPT回答的方向与官网介绍并不相同。个人觉得ChatGPT还是通过大量的语料学习到类似问题的回答方式,根据海量训练数据以及人工反馈的修正,生成对应的结果。
Q2: ChatGPT中工程逻辑有多少?
ChatGPT针对无准确答案的回答,带有偏见的回答,都会表明自己不具备相关能力,并给出解决方式。这种方式到底是训练过程给了足够的数据,还是通过工程手段匹配得到的呢?
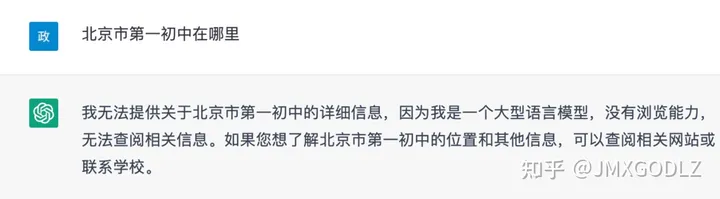
Q3: ChatGPT能否直接取代搜索引擎结果?
ChatGPT搜索结果的准确性还不够高。正如InstructGPT论文中所说,该模型还是会生成错误答案,无法根据描述生成句子、虚构事实、对简单问题给出长时间的模糊答案,或者无法检测到带有虚假前提的指令。
例如,下面是一个脑筋急转弯题目:
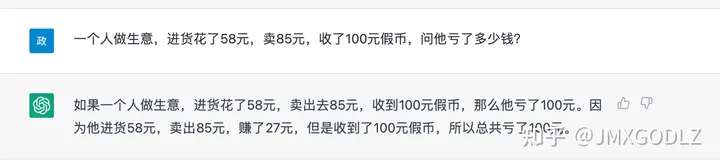
看上去生成的没什么问题,但是细看却无逻辑性。实际应该是进货花了58,找钱花了15,因此总共亏了73元。










![文件夹 英文(2022年9月最新美区iOS账号分享[美国AppStore游戏下载必备账号])-梦马网络](https://blog.csqc8.com/uploads/allimg/20220914/1-2209141HH4319.jpeg)
