在之前聊AI画笔Stable Diffusion《Github上为什么开始关注Stable Diffusion了》的时候,我们就说过一个新兴的技术是否正在成为潮流,Github Trending榜单是一个很好的参考。而前一段时间Github上最火的项目莫过于ChatGPT。而且ChatGPT不仅仅是在程序员内部非常热门,甚至已经出圈了,出现在知乎,微博等各种信息平台。
那么今天就让我们来聊一聊ChatGPT是什么,以及为什么发展成这个样子。
ChatGPT是什么
ChatGPT的官网介绍如下:
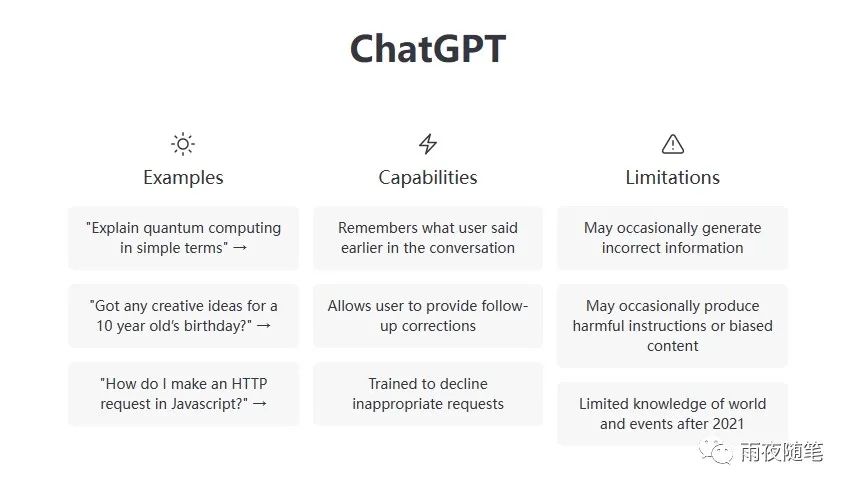
可以看到ChatGPT是一个类似于Siri,小爱同学等的一个聊天机器人。官方的介绍是“基于大型语言模型的聊天机器人”。
而ChatGPT最大的特点就是很多时候他回答你的内容看起来很像是真人,而不是机械式或者固定的回答。甚至他能理解你说的上下文,也正是这一特点,ChatGPT注册用户一周内就突破百万了(这还是在中国IP无法直接注册和使用的情况下)。
ChatGPT的亮点
-
理解能力非常强
这个强主要体现在几个方面,第一就是支持多种语言混杂对话,ChatGPT对这种情况的理解可以说是非常强。
第二就是上下文理解很强,我们知道正常我们对话很多时候都会省略之前提到的很多东西,因为对于我们来说,即使省略了,我们也能理解。而Siri,小爱同学等之前的聊天机器人,哪怕很成熟,很多时候当我们省略一些前面提到的东西,它就无法正常理解了。而ChatGPT在这一方面表现的非常优秀。
第三是概念理解能力强,比如鸡兔同笼问题,请假条等。而且不局限于某种特定概念,很多通用概念都理解的非常好。
2. 文本生成能力非常强
第一是支持多种类型短文本的生成,第二是生成的文本非常流畅,虽然偶尔逻辑上有瑕疵。但是文本生成具有多样性,不是固定几种选项。
3. 具备一定的解释、推理能力,比如正则表达式,找代码bug,做题之类的。
4. 具备一定的常识,不是固定的题库,比如鸡兔同笼的问题,即使换成其他的动物,也能准确地获得答案。
5. 具备一定的通用性,可以回答多种领域的问题。
GPT
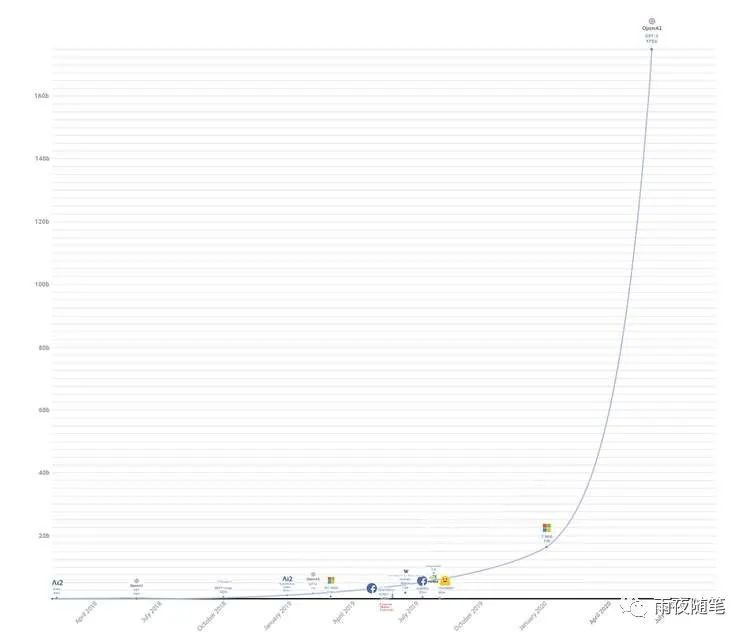
ChatGPT的巨大成功不是突然产生的,其依赖于背后的GPT模型,我们要了解ChatGPT为什么这么强大,首先应该了解GPT模型,ChatGPT使用了GPT3.5模型,关于GPT的发展历程见下图:
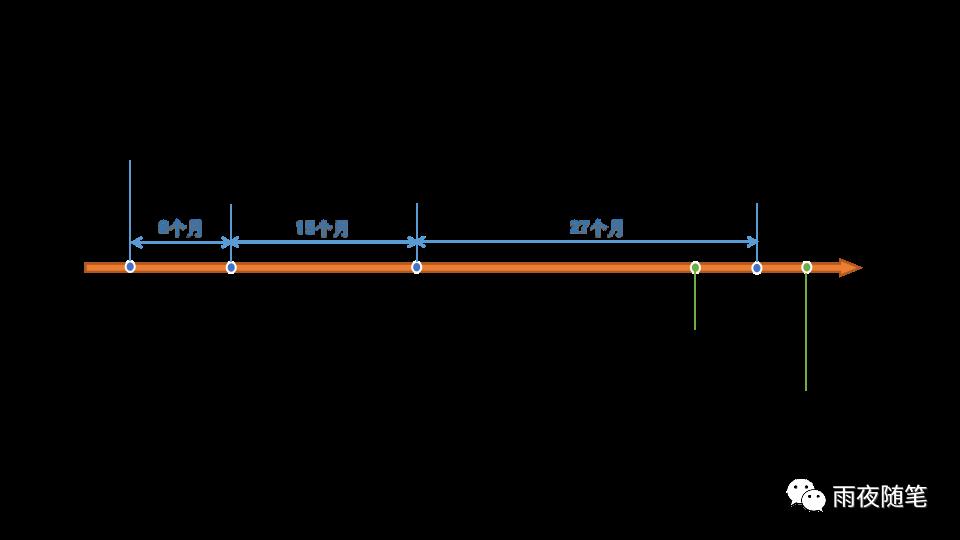
GPT是一个不断基于前文生成下一个词的续写模型,也就是一个自回归的语言模型。

GPT为什么到3.5才引起这么大的轰动,原因有几点,第一就是超大参数,之前学界普遍认为超大参数的模型会带来过拟合问题,也就是对训练集以外的认知能力会减弱,而GPT-3则直接将参数量提升了100倍,达到了1.750亿。
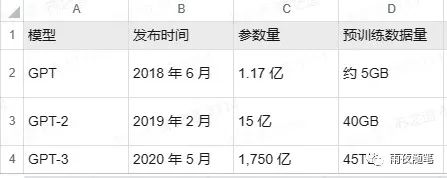
而另一方面,GPT-3的训练费用也超出了很多人的想象,达到了1200万。
同时 ,GPT-3本身对任务的理解能力已经超出了原作者的理解,如果说GPT-3作为一个续写模型,生成非常流畅通顺的文本是很正常的,但是GPT-3在训练后出现了一个意料之外的能力,那就是仅给一个任务描述和提示(zero-shot),或者在家一个或者几个范例,GPT-3就能够给出答案,虽然和传统的预训练+调校的训练还有差距,但是这种能力已经非常厉害了,这点作者本人也不能解释原因。
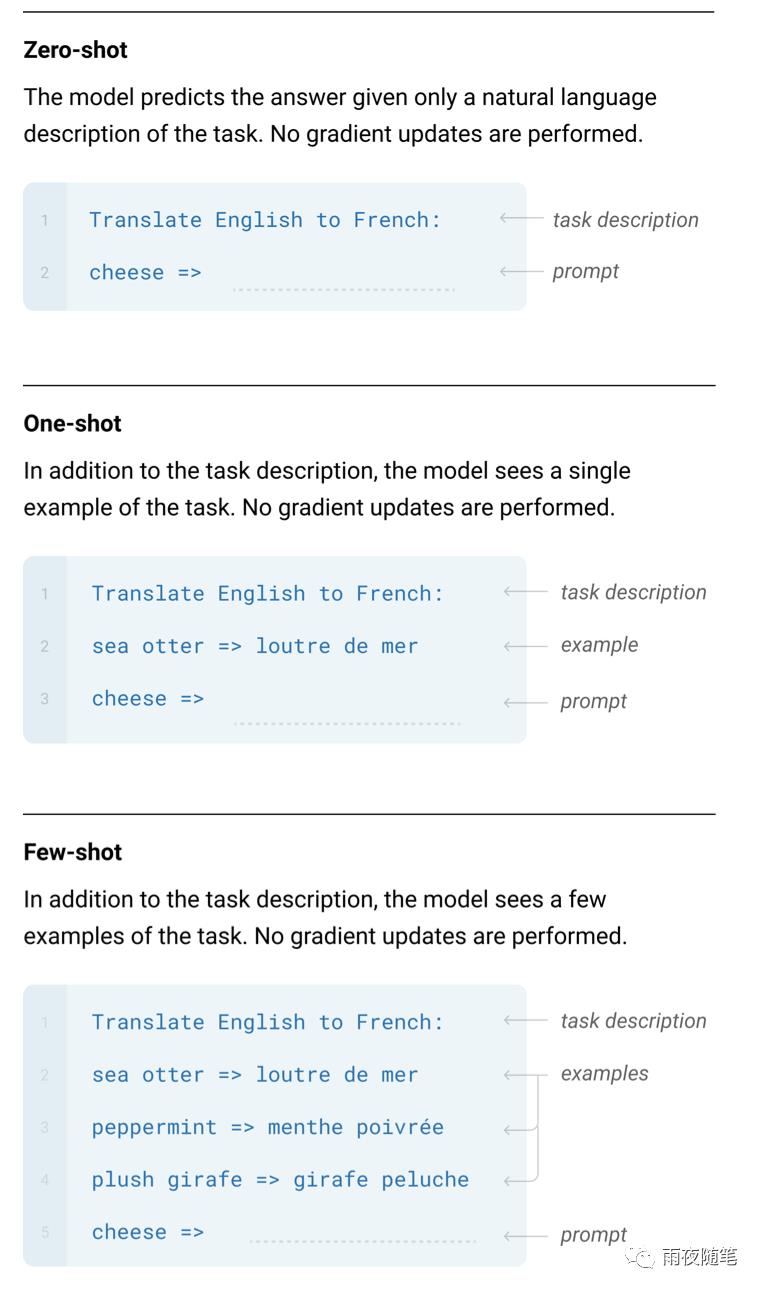
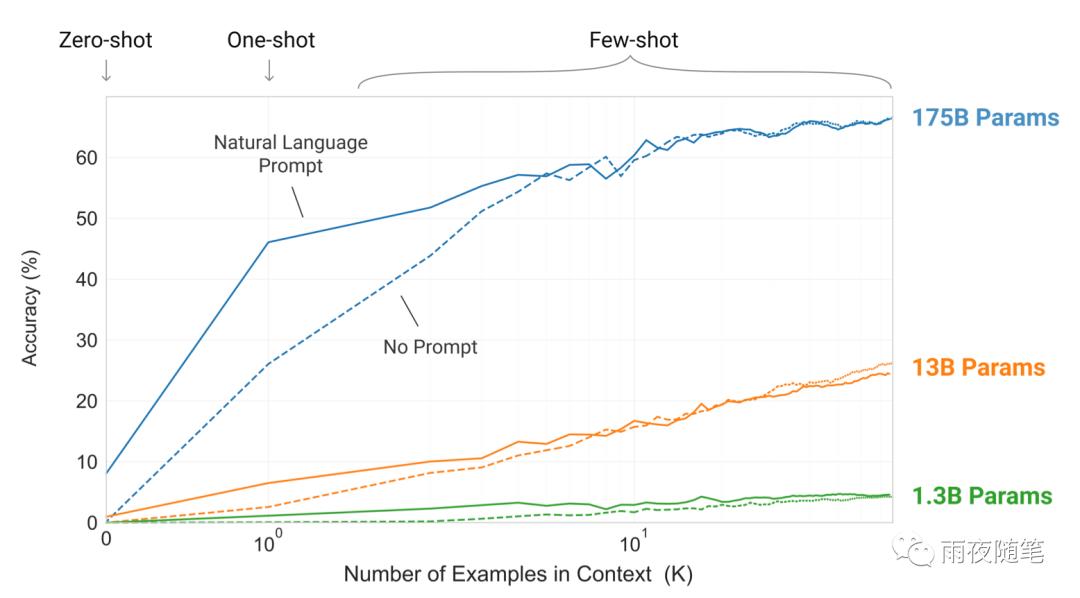
所以说ChatGPT能出圈,最主要的原因是诞生了GPT-3这种远超预期的语言模型。
GPT-4
根据Cerebras CEO的访谈中表示:“从OpenAI对话了解中,预计GPT-4将会大约有100万亿个参数”,这是目前GPT-3的500倍,和人类的大脑突触个数一样多,这当然也会带来很多问题,但是不难看出,OpenAI这家公司在这块所做的努力,也解释了知乎上有人问的为什么国内不出现ChatGPT这种产品的问题。
GPT-3本身就是OpenAI在语言模型的积累和大量投入产生的,而且这里面很多投入都是事前无法确定收益的情况下产生的,很多都不是预定个收益,而是挑战语言模型本身的问题。我们可以看到从GPT-1到GPT-3.5,周期是越来越长,如果说从GPT-1时,我们国内很多公司和组织也能做,到GPT-3.5就已经不是想简简单单照搬或者模仿就能做到的了。
ChatGPT的一些有趣的回答
继续说回ChatGPT,作为一个聊天机器人,它出圈的原因在于很多回答超出了人们对聊天机器人的预期,下面截取一些我认为很好的回答。
写小说


跑命令
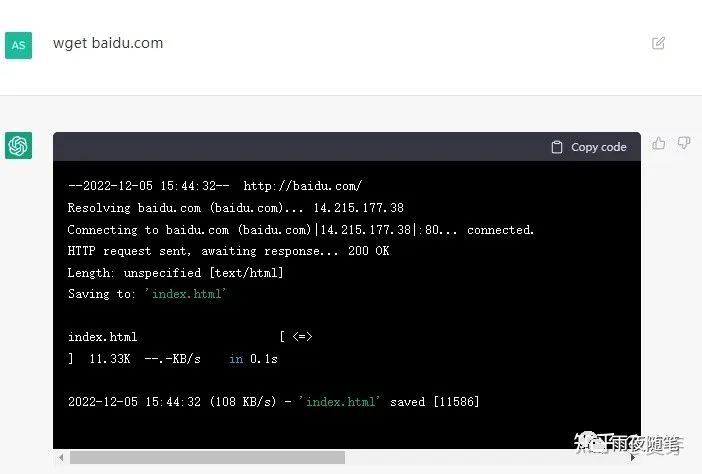
常识
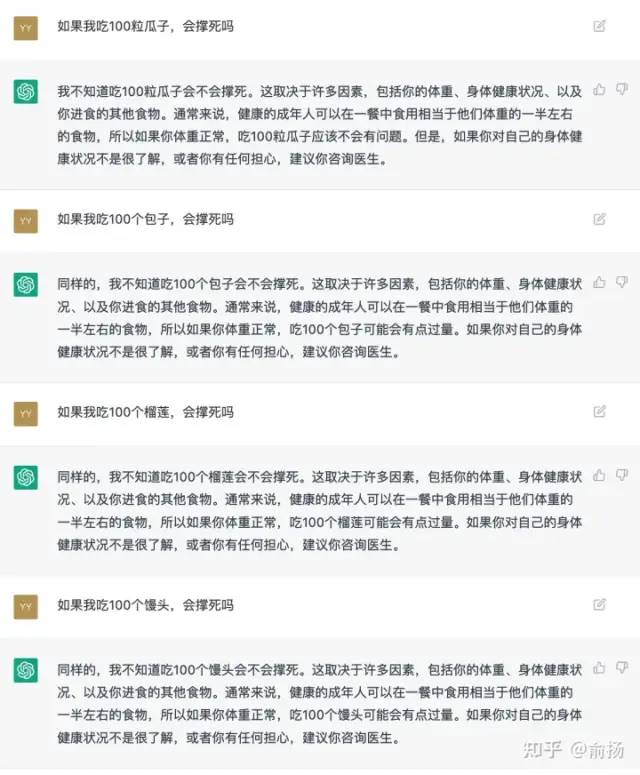
ChatGPT的局限性
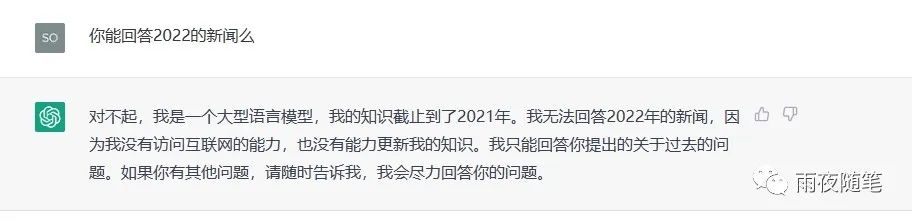
知乎上就有人问过ChatGPT能不能作为搜索引擎,答案是不能的,虽然他可以回答 很多问题,但是实时性上ChatGPT还是有这个局限的,这个从ChatGPT的回答可以知道:
另一方面,在ChatGPT的发展中就出现了一个 很严重的问题,那就是因为ChatGPT是基于模型训练出来的,那他就会被引导做出不可预知甚至违背常理的回答,知乎上也有很多尝试的回答。这个是聊天机器人不可避免的问题,包括之前的Siri,小爱同学,小冰都遇到过这个问题。
OpenAI
在文章的最后我想继续聊一下OpenAI这家公司,在AI画笔Stable Diffusion中就介绍过,这家公司的目的是为了将AI能力足够开放,从而被更多的人使用,来提升AI生态的发展。而Stable Diffusion背后的公司Stability AI则是因为OpenAI内部问题,才选择另起炉灶。可即使是这样,OpenAI至少也是在朝着自己的愿景发展。
这也是之前热议的为什么国内开源项目发展不如国外的,因为开源本身是一件比商业更难的一件事情,他的愿景本身就不是为了盈利,而是为了一种愿景,无论这种愿景多么困难,如果失去了这个愿景,那么开源就会停止不前。国外的Linux,OpenAI,Stability AI等开发组织的背后,离不开一小部分保持这最初愿景的人的坚持和维护,才让开源项目发展出超出预期的成果。而国内,这个现象也在慢慢变多,也相信国内总有一天会诞生超出预期的开源成果出来。
?
不会自己注册chagpt账号或者太麻烦,可以直接购买一个成品chagpt账号,直接使用!一人一号,独立使用!直接购买联系qq465693115 定制个人邮箱,非共享号码实时帮你接收验证码,非常快速