【新智元导读】自己部署一个ChatYuan,再也不用担心网络拥堵了!
如何使用
1. Github
项目地址:https://github.com/clue-ai/ChatYuan
2. Huggingface

项目地址:https://huggingface.co/ClueAI/ChatYuan-large-v1


3. ModelScope

项目地址:https://modelscope.cn/models/ClueAI/ChatYuan-large
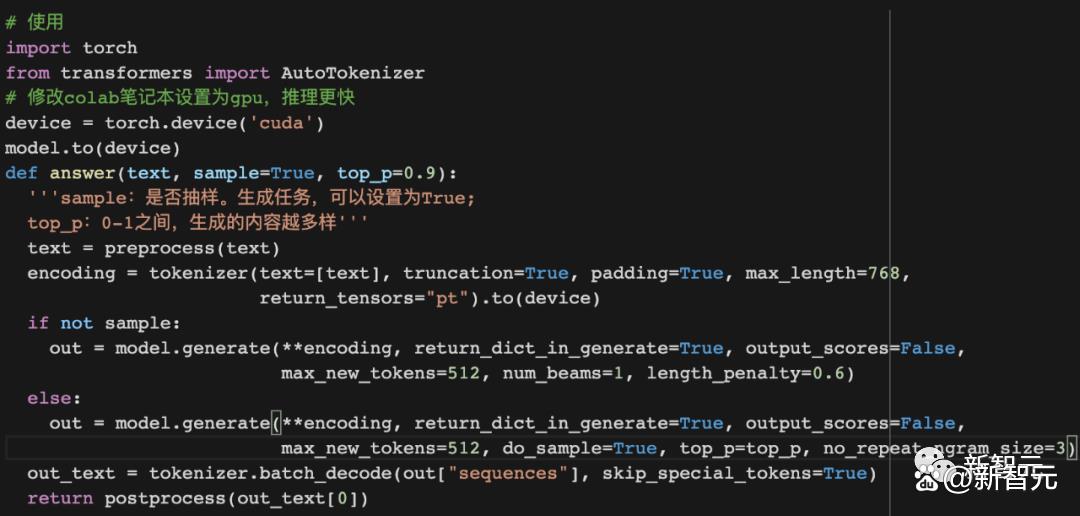
加载模型:

使用模型进行预测推理方法:


4. PaddlePaddle

项目地址:https://aistudio.baidu.com/aistudio/projectdetail/5404182
模型地址:https://huggingface.co/ClueAI/ChatYuan-large-v1-paddle
使用自有数据训练模型
输入(Input):任务描述+输入文本
输入(Input):任务描述+上文+输入文本


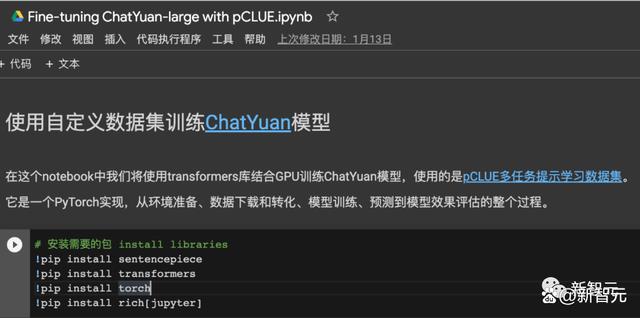
举个例子
==========示例1==========
用户:
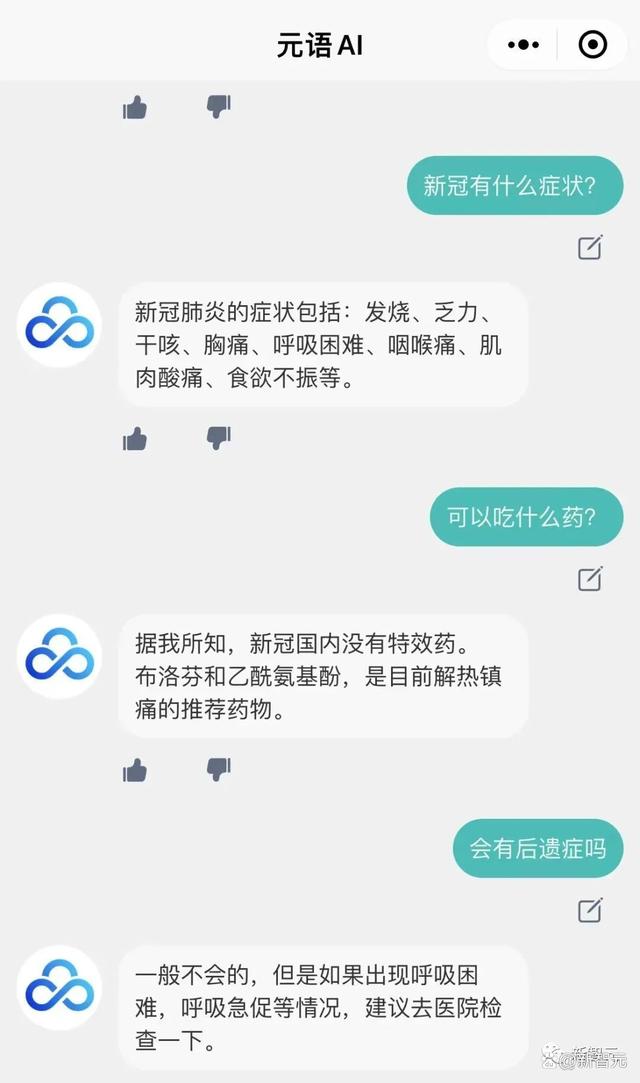
你能干什么
小元:
您好!我是元语AI。我可以回答您的问题、写文章、写作业、翻译,对于一些法律等领域的问题我也可以给你提供信息。
==========示例2==========
用户:
写一个诗歌,关于冬天
小元:
冬夜寂静冷,
云在天边飘,
冰封白雪上,
寒冷像一场雪。
雪花融化成冰,
像那雪花飘洒,
在寒冷的冬天,
感受春天的喜悦。
冬日里,
风雪渐消,
一片寂静,
把快乐和温暖带回家。
==========示例3==========
用户:
学前教育专业岗位实习中,在学生方面会存在问题,请提出改进措施。800字
小元:
在学前教育专业岗位实习中,在学生方面会存在一些问题,如学生缺少专业知识、缺乏合作意识、缺乏基本的责任心等等,需要我们采取措施,来解决这些问题。
首先,在实习过程中,我们需要培养学生的团队意识,加强学生与老师之间的合作,加强与家长之间的沟通,提高他们的沟通能力。另外,我们也需要加强学生的独立性,让学生学会独立思考,学会和老师、家长进行沟通,培养其独立性。
此外,在日常的工作中,我们也要为学生提供适当的机会和机会,让学生多接触社会、多参加社会活动,加深他们对社会、学校的认识,培养他们主动、积极和创新的精神。
最后,我们还需要重视学生在实习中出现的问题,尤其是学生缺乏合作,有依赖心理,不懂得分享,有拖延行为等,这些学生应该引起我们的重视,制定合理的改进措施,改善这些问题。
技术与训练过程
技术与训练过程
ChatYuan是在PromptCLUE基础上进一步训练获得的模型。它去掉了文本理解、信息抽取类任务,加强了问答、对话和各种生成式任务的学习和训练;
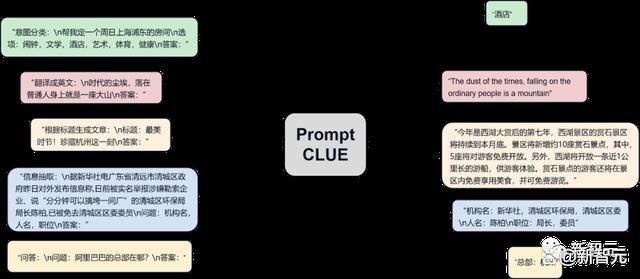
-
三大统一:统一模型框架(text-to-text),统一任务形式(prompt),统一应用方式(zero-shot/few-shot)(T0)
-
大规模预训练:在t5-large版基础上,使用数百G中文语料,训练了100万步,累积训练了1.5万亿个中文字词级别token
-
大规模任务数据:使用了16种任务类型,数百种任务,累积亿级别任务数据
-
混合预训练:一方面将下游任务作为预训练语料,另一方面将下游任务和预训练语料一起训练,减少任务灾难遗忘以及缩短预训练和下游任务的距离,更好的适应下游任务(ExT5)
-
混合采样:针对众多数据量差异极大的任务,采用在每个训练batch内对所有的任务进行按照比例采样,根据任务的数据量进行平滑采样,并且同时限制任务数据量采样池的上限。平滑采样可以减少任务训练有偏危害,在每一batch内训练可以减少异质任务之间训练负迁移的情况(T5)
-
分阶段训练:一方面指在预训练分阶段,涉及训练序列长度的分阶段(128和512),加快预训练速度(Bert);另一方面,在下游训练分阶段, 涉及学习率和序列长度的变化以及递减式对下游任务的数据量限制,更好的适应下游的不同任务。
-
增加语言模型的训练:参考t5.1.1, 除了使用Span Corrpution构建的方式进行无监督训练,同时在使用prefix LM的方式训练,增强生成任务的能力(LM adapted)
-
增加对模型的encoder以及decoder的训练:根据下游任务数据分别构建Data_text,Data_target预训练数据语料,加入到预训练中,分别增强模型的encoder理解能力和 decoder的生成能力(见UIE)
-
重新构建模型中文字典:使用sentencepiece上在千亿token上学习并构建模型字典,更加符合中文语言习惯
后续工作