1、前言
从整体技术路线上来看,ChatGPT使用了GPT-3.5大规模语言模型(LLM,Large Language Model),并在该模型的基础上引入强化学习来Fine-turn预训练的语言模型。这里的强化学习采用的是RLHF(Reinforcement Learning from Human Feedback),即采用人工标注的方式。目的是通过其奖励惩罚机制(reward)让LLM模型学会理解各种NLP任务并学会判断什么样的答案是优质的(helpfulness、honest、harmless三个维度)。
因此在了解ChatGPT之前,我们需要先看看什么是GPT-3以及强化学习。
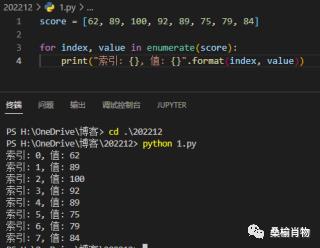
1.1、GPT
OpenAI 在 2018 年 6 月提出的预训练模型GPT(也就是GPT-1)采用自回归的预训练方式,更适合自然语言生成任务的场景。它和Bert一样,不仅同样是预训练模型,而且都是源自于transformer,采用的是Transformer-Decoder作为编码器,在transformer基础上,它进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT只保留了 Masked Multi-Head Attention,如下图所示:
和Bert不同的是,它作为语言模型是利用上文预测下一个单词的, Decoder 使用了 Masked Multi Self-Attention 屏蔽了单词的后面内容,所以 Decoder 是现成的语言模型。又因为没有使用 Encoder,也就不需要 encoder-decoder attention 了。
GPT-2 主要就是在 GPT 的基础上,添加了多个任务,扩增了数据集和模型参数,又训练了一番。把各种NLP任务的数据集添加到预训练阶段。即把机器翻译、文本摘要、领域问答统统往预训练里加。既然多个任务都在同一个模型上进行学习,那么这一个模型能承载的并不仅仅是任务本身,“汪小菲的妈是张兰”,这条文字包含的信息量是通用的,它既可以用于翻译,也可以用于分类,判断错误等等。也就是说,信息是脱离具体 NLP 任务存在的,举一反三,能够利用这条信息,在每一个 NLP 任务上都表现好,这个是元学习(meta-learning)。本质上就是语言模型的一脑多用。此时,GPT-2相较于前一代,参数量和训练数据都已经有了爆发式的增长。
GPT-3,以往的预训练都是两段式的,即,首先用大规模的数据集对模型进行预训练,然后再利用下游任务的标注数据集进行 finetune,时至今日这也是绝大多数 NLP 模型任务的基本工作流程。
GPT-3 就开始颠覆这种认知了。它提出了一种 in-context 学习方式。即给模型输入一定的提示和范例,比如用户输入到 GPT-3:请把以下中文翻译成英文:苹果 => apple; 你觉得 ChatGPT怎么样=>
其中 苹果翻译成 apple,是一个示范样例,用于让模型感知该输出什么。只给提示叫做 zero-shot,给一个范例叫做 one-shot,给多个范例叫做 few-shot。在 GPT-3 的预训练阶段,也是按照这样多个任务同时学习的。比如“做数学加法,改错,翻译”同时进行。这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。但是这里需要超大模型才行得通,如下图所示:
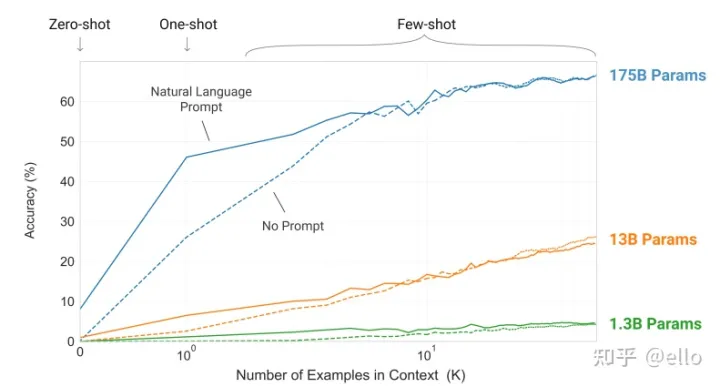
可以看出,这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。
下表是三代GPT之间参数量的比较。
| 模型 | 数据量 | 参数量 |
|---|---|---|
| GPT-1 | 约 5GB | 1.17亿 |
| GPT-2 | 40GB | 15亿 |
| GPT-3 | 45TB | 1750亿 |
1.2、强化学习
强化学习是一种和有监督、无监督学习并行的概念。用游戏比较好理解,有代理(游戏角色)、环境、目标、行动、反馈这些基本要素。它会在给定的环境中,不断地根据环境的惩罚和奖励(reward),拟合到一个最适应环境的状态,是一种通过试错来进行学习的模型。
之前的研究中一直没有在NLP+强化学习上取得好的效果,主要是因为NLP 所依赖的环境,是整个现实世界,整个宇宙万物,都可以被语言描述,也就都需要针对模型输出的质量进行 reward 评价,它完全无法设计反馈惩罚和奖励函数。除非人们一点点地人工反馈。
下面说到今天的主角,ChatGPT正是openAI不计成本进行大量人工标注将GPT和强化学习结合起来得到的产物,具体方法分为以下三个阶段。
以下对ChatGPT的介绍主要来源自instructGPT的论文,ChatGPT是改进的instructGPT,改进点主要在收集标注数据方法上有些区别,在其它方面,包括在模型结构和训练流程等方面基本遵循instructGPT。
2、Chatgpt的三个阶段
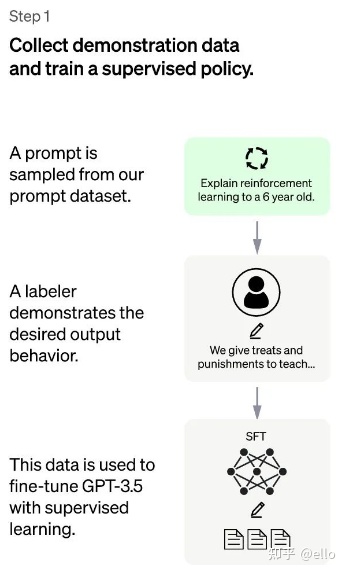
2.1、冷启动阶段
该阶段的输入是从测试用户提交的prompt(就是指令或问题)中随机抽取的一批数据,其例子如下所示:

其方法概括来讲,就是以下两个部分,如下图所示:
- 对抽取的prompt数据人工进行高质量回答,获得<prompt,answer>数据对。
- 通过高质量回答fine-turn
gpt-3.5模型,在第一阶段帮助模型更好地理解输入指令。
这样,一个基本的 GPT-3.5语言模型就被学习成了这里的 SFT 模型。
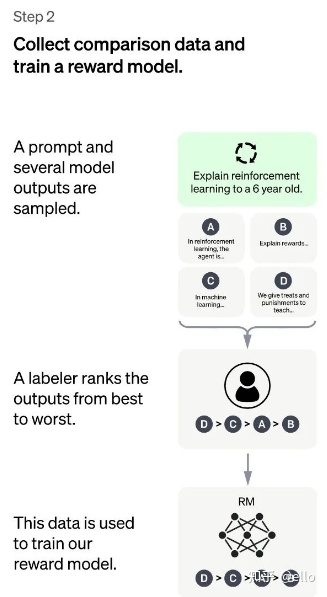
2.2、训练回报模型阶段(RM)
训练回报模型(RM) ,如下图所示,其方法概括为如下两部分
- 用上一阶段fine-turn好的SFT模型(使用和第一阶段几乎相同的prompt)生成k个回答(这里需要注意,对于同一个问题,GPT和SFT模型生成的答案是多样的,每一次提问都会由不同的答案),人工标注排名顺序
- 用排序结果训练数据对<prompt,answer>
我们希望被判定更好的输出得到的奖励数值要更高。由此,奖励模型可以通过最小化下面这样的损失函数来得到。对于一对训练数据<answer1,answer2>,我们假设人工排序中answer1排在answer2前面,那么Loss函数则鼓励RM模型对<prompt,answer1>的打分要比<prompt,answer2>的打分要高。

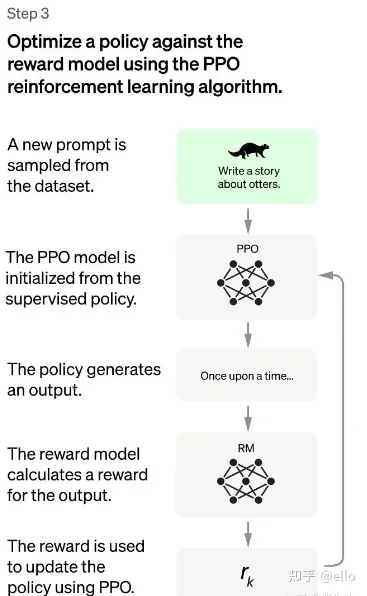
2.3、强化学习微调阶段
这一步数据集规模更大一些且和第一二阶段不同,且不再需要人工。其方法可以概括为以下四个部分:
- 由第一阶段的监督模型初始化PRO模型的参数
- PRO模型生成回答
- 用第二阶段RM模型对回答进行评估和打分
- 通过打分,更新训练PRO模型参数
这一步的训练过程中,还不仅仅使用强化学习的优化目标。还使用了下面的两个正则项来约束模型的表现。我们需要在训练的过程中最大化下面的函数,当γ≠0时,模型变为PRO-ptx(加上该部分是因为仅仅使用RL来学习可能会使得模型在很多NLP任务性能上下降)。

总结一下:RLHF用于第一二阶段,首先通过人工标注微调gpt模型得到SFT模型,用SFT模型生成k个回答人工排序,训练RM模型。第三阶段,把SFT模型参数拿来,用RM模型获得的reward进行训练,得到pro和pro-ptx模型。
3、实验与模型的衡量
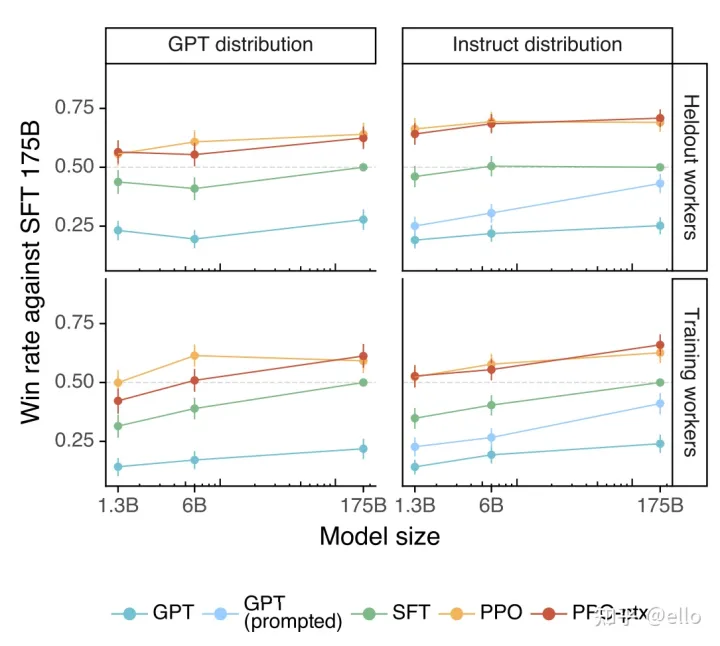
3.1、helpful
- helpful——是否可以推断用户意图
- 测试方法是标注员在待测试模型的输出和 SFT 模型的输出中选择一个更好的。如果得分为 0.5 则表示该模型和 SFT 相比性能差不多。下图左侧为GPT提供prompt,右侧即为instructGPT提供的prompt测试得到的结果。可以看出pro和pro-ptx模型相对于其它模型取得了更好的效果。
3.2、honest
方法是在模型前加上如下这样的 instruction prompt,提示模型该小心什么问题,该怎样回答。

结果如下,右图即为加上instruction的效果。其中灰色代表可信度,有颜色的即代表同时可信和包含信息量的额比率:
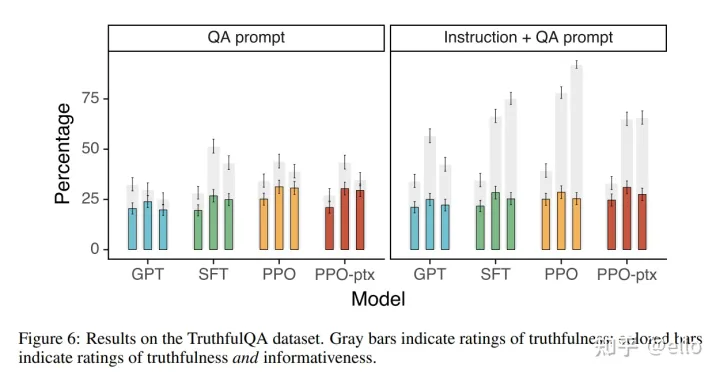
3.3、harmless
方法也是加上instruction,从而减少模型产生有害/不礼貌/带有偏见的回答,效果如下所示:
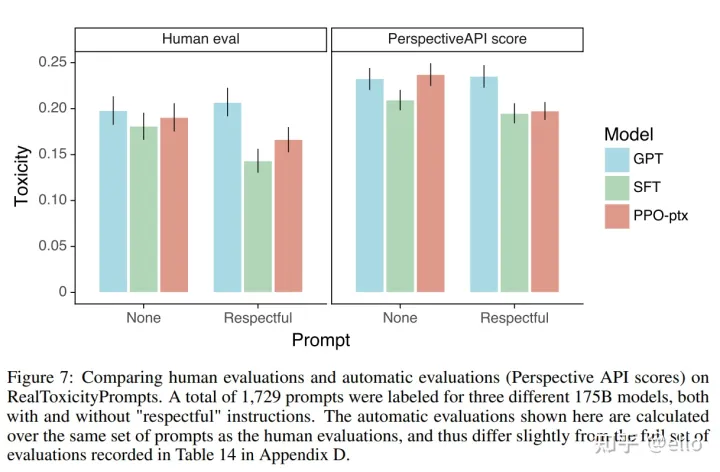
可以看出,pro和pro-ptx模型在三个H的评判指标下都取得了不错的结果。
4、问题与总结
4.1、模型优点
- 相对于自回归模型,reward有更细致的处罚信号,比如如果下一token是great,AR loss会给amazing和sandwich相同的处罚
- offline模式,使得RM模型生成更合适的反馈。
- RM模型更直接获取偏好
- 直接根据偏好进行打分
- 好的句子就是高的反馈
- 运用数据更具有效率
- SFT需要人来生成目标,在我们训练RM的时候,就可以用来为输出打分了
4.2、挑战与问题
高效引入新的知识困难,因为它是通过在GPT大模型上大量添加人工标注数据进行训练,重新训练的成本太大,而如果通过fine-turn对引入的新知识进行调整,可能会产生对于之前的知识灾难性遗忘的问题。
对于同一问题可能产生不同答案,且有可能会生成看似合理但实际完全错误的答案,不好判断。
4.3、一些思考
个人认为,ChatGPT最主要的贡献是还是证明了大力出奇迹,以及NLP+强化学习的方式能够取得很好的表现。过去的做对话的思路都是分出各个子任务逐个击破,再加以整合。而ChatGPT的成功则说明,不用考虑琐碎的细节,大模型大数据能够取得更好的效果。当然,这对于像我这样的nlp初学者来说,可能确实没有什么可以借鉴的地方。但是它取得的效果也确实足够令人激动。
以上是本人在学习和了解过程中的一些总结和思考,可能有一些不到位的地方,欢迎各位大佬讨论指正。
参考链接:
1.https://arxiv.org/pdf/2203.02155.pdf——InstructGPT
2.【强化学习 229】ChatGPT/InstructGPT – 知乎 (zhihu.com)